
Scalabilità più intelligente: come i team IT aziendali possono dimensionare correttamente il proprio computer per l'intelligenza artificiale

Questo articolo fa parte del numero speciale di VentureBeat, "Il vero costo dell'intelligenza artificiale: prestazioni, efficienza e ROI su larga scala". Scopri di più su questo numero speciale.
I progetti pilota di intelligenza artificiale raramente iniziano con una discussione approfondita su infrastruttura e hardware. Ma gli esperti di scalabilità avvertono che l'implementazione di carichi di lavoro di produzione ad alto valore non avrà un esito positivo senza un'attenzione strategica e continuativa a una base fondamentale di livello enterprise.
Buone notizie: le aziende stanno riconoscendo sempre più il ruolo fondamentale che l'infrastruttura svolge nell'abilitare e nell'espandere applicazioni generative, agentive e altre applicazioni intelligenti che generano fatturato, riduzione dei costi e guadagni di efficienza.
Secondo IDC , nel 2025 le organizzazioni hanno aumentato la spesa per infrastrutture hardware di elaborazione e storage per le implementazioni di intelligenza artificiale del 97% rispetto allo stesso periodo dell'anno precedente. I ricercatori prevedono che gli investimenti globali in questo settore passeranno dagli attuali 150 miliardi di dollari a 200 miliardi di dollari entro il 2028.
Ma il vantaggio competitivo "non va a chi spende di più", ha affermato John Thompson, autore di best-seller sull'intelligenza artificiale e responsabile della divisione Gen AI Advisory di The Hackett Group in un'intervista con VentureBeat, "bensì a chi scala in modo più intelligente".
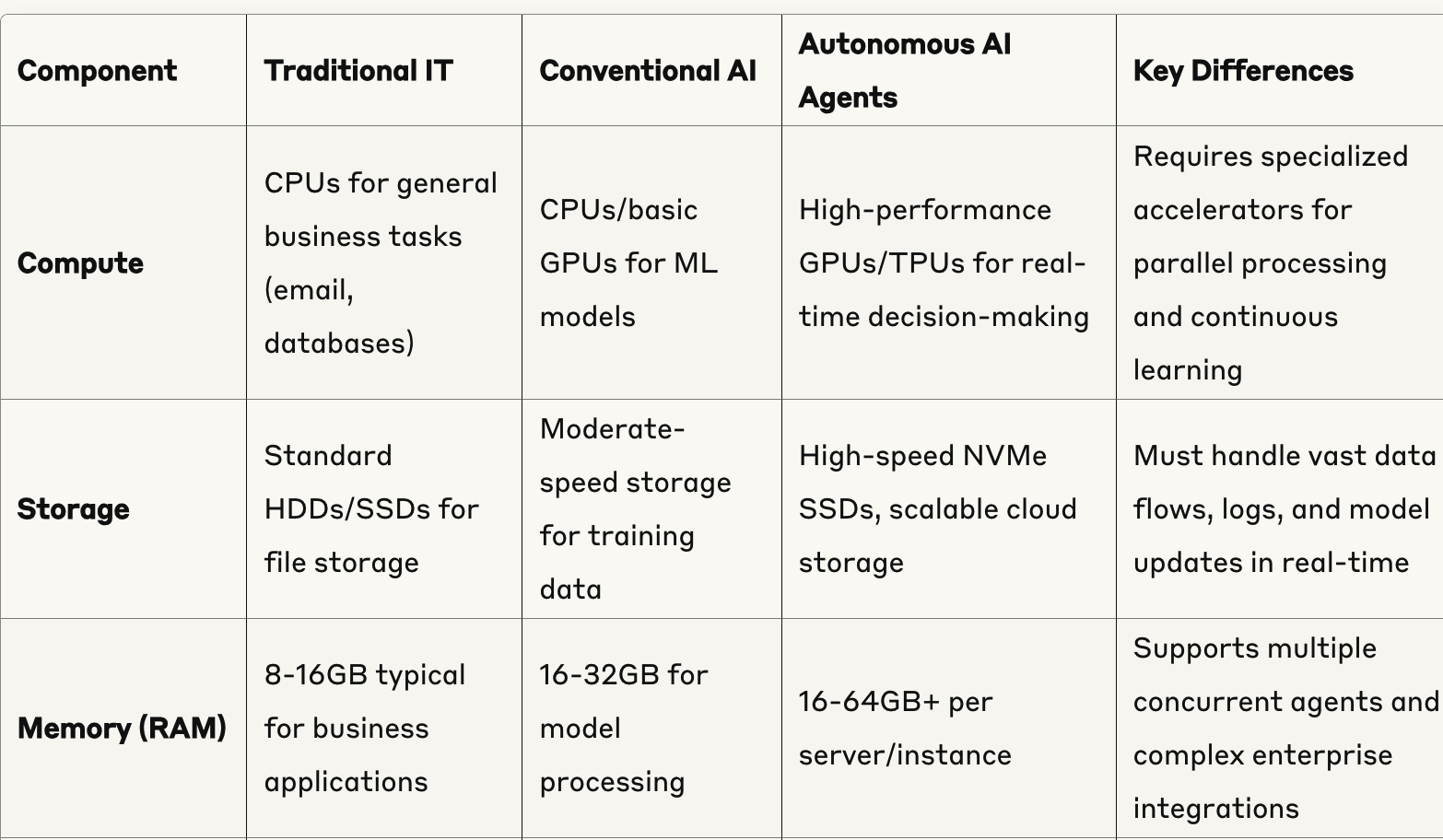
Altri esperti concordano, affermando che le probabilità che le aziende possano espandere e industrializzare i carichi di lavoro di intelligenza artificiale sono pressoché nulle senza un'attenta pianificazione e il corretto dimensionamento della rete finemente orchestrata di processori e acceleratori , nonché di sistemi di alimentazione e raffreddamento aggiornati. Questi componenti hardware appositamente progettati offrono la velocità, la disponibilità, la flessibilità e la scalabilità necessarie per gestire volumi di dati, spostamenti e velocità senza precedenti, dall'edge all'on-prem al cloud.

Fonte: VentureBeat
Studio dopo studio, si identificano problematiche legate all'infrastruttura, come colli di bottiglia nelle prestazioni, hardware non compatibile e scarsa integrazione legacy, oltre a problemi di dati, come i principali killer dei progetti pilota. L'interesse e gli investimenti crescenti nell'IA agentica aumentano ulteriormente la posta in gioco tecnologica, competitiva e finanziaria.
Tra le aziende tecnologiche, un indicatore di riferimento per l'intero settore, quasi il 50% ha in corso progetti di intelligenza artificiale basata su agenti; le restanti li avvieranno entro 24 mesi. Stanno destinando metà o più dei loro attuali budget per l'intelligenza artificiale all'analisi agenti, e molte prevedono ulteriori aumenti quest'anno. (Un vantaggio, perché questi complessi sistemi autonomi richiedono GPU e TPU costose e rare per operare in modo indipendente e in tempo reale su più piattaforme.)
Grazie alla loro esperienza con i piloti, i leader tecnologici e aziendali ora comprendono che i severi requisiti dei carichi di lavoro dell'intelligenza artificiale (elaborazione ad alta velocità, networking, storage, orchestrazione e immensa potenza elettrica ) sono diversi da qualsiasi cosa abbiano mai realizzato su larga scala.
Per molte aziende, la domanda urgente è: "Siamo pronti a farlo?" La risposta onesta sarà: non senza un'attenta analisi continua, una pianificazione e, probabilmente, aggiornamenti IT non banali.
Come i fiocchi di neve e i bambini, ci viene ricordato che i progetti di intelligenza artificiale sono simili ma unici. Le esigenze variano notevolmente tra le varie funzioni e tipologie di intelligenza artificiale (addestramento contro inferenza, apprendimento automatico contro rinforzo). Allo stesso modo, esistono ampie discrepanze negli obiettivi aziendali, nei budget, nel debito tecnologico, nel lock-in con i fornitori e nelle competenze e capacità disponibili.
Com'è prevedibile, quindi, non esiste un approccio "migliore". A seconda delle circostanze, si scalerà l'infrastruttura di IA in verticale (più potenza per carichi maggiori), in verticale (aggiornando l'hardware esistente) o in modo ibrido (entrambi).
Tuttavia, queste mentalità, principi, raccomandazioni, pratiche, esempi concreti e trucchi per risparmiare sui costi, già introdotti nei primi capitoli, possono aiutarti a concentrarti e a mantenere gli sforzi nella giusta direzione.
È una sfida di vasta portata, con molti livelli: dati , software, networking, sicurezza e storage. Manterremo l'attenzione alta e includeremo link ad approfondimenti utili e correlati, come quelli sopra.
Il più grande cambiamento di mentalità consiste nell'adottare una nuova concezione dell'intelligenza artificiale: non come un'app autonoma o isolata, ma come una capacità fondamentale o una piattaforma integrata nei processi aziendali, nei flussi di lavoro e negli strumenti.
Per far sì che ciò accada, l'infrastruttura deve bilanciare due ruoli importanti: fornire una base aziendale stabile, sicura e conforme, e al contempo semplificare l'implementazione rapida e affidabile di carichi di lavoro e applicazioni di intelligenza artificiale appositamente progettati, spesso con hardware su misura ottimizzato per domini specifici come l'elaborazione del linguaggio naturale (NLP) e l'apprendimento per rinforzo.
In sostanza, si tratta di un'importante inversione di ruoli, ha affermato Deb Golden, responsabile dell'innovazione di Deloitte. "L'intelligenza artificiale deve essere trattata come un sistema operativo, con un'infrastruttura che si adatti ad essa, non il contrario".
Ha continuato: "Il futuro non riguarda solo modelli e algoritmi sofisticati. L'hardware non è più passivo. [Quindi, d'ora in poi], l'infrastruttura consisterà fondamentalmente nell'orchestrare l'hardware intelligente come sistema operativo per l'intelligenza artificiale".
Per operare in questo modo su larga scala e senza sprechi è necessario un "tessuto fluido", il termine con cui Golden definisce l'allocazione dinamica che si adatta in tempo reale su ogni piattaforma, dai singoli chip di silicio fino ai carichi di lavoro completi. I vantaggi possono essere enormi: il suo team ha scoperto che questo approccio può ridurre i costi dal 30 al 40% e la latenza dal 15 al 20%. "Se l'IA non respira con il carico di lavoro, è soffocante".
È una sfida impegnativa. Tale infrastruttura di intelligenza artificiale deve essere multilivello, cloud-native, aperta, in tempo reale, dinamica, flessibile e modulare. Deve essere orchestrata in modo altamente e intelligente su dispositivi edge e mobili, data center on-premise, PC e workstation con intelligenza artificiale e ambienti cloud ibridi e pubblici.
Quello che sembra un bingo di parole d'ordine rappresenta una nuova epoca nell'evoluzione in corso, che ridefinisce e ottimizza l'infrastruttura IT aziendale per l'intelligenza artificiale. Gli elementi principali sono familiari: ambienti ibridi, un universo in rapida crescita di servizi, framework e piattaforme basati sul cloud sempre più specializzati.
In questo nuovo capitolo, adottare la modularità architettonica è fondamentale per il successo a lungo termine, ha affermato Ken Englund, responsabile della crescita tecnologica di EY Americas. "La capacità di integrare diversi strumenti, agenti, soluzioni e piattaforme sarà fondamentale. La modularità crea flessibilità nei framework e nelle architetture."
Il disaccoppiamento dei componenti dei sistemi contribuisce a garantire la sicurezza futura in diversi modi, tra cui l'agnosticismo rispetto a fornitori e tecnologie, il miglioramento del modello lug-and-play e l'innovazione e la scalabilità continue.
I team tecnologici aziendali che desiderano ampliare l'uso dell'intelligenza artificiale aziendale si trovano ad affrontare una nuova sfida fondamentale: trovare i livelli di investimento "giusti" in infrastrutture e hardware nuovi e moderni in grado di gestire le richieste in rapida crescita e in continua evoluzione dell'intelligenza artificiale distribuita ovunque.
Investire poco o restare fedeli alle attuali capacità di elaborazione? Si rischiano colli di bottiglia nelle prestazioni e risultati aziendali deludenti, che possono mandare all'aria interi progetti (e carriere).
Investire troppo in una nuova, scintillante infrastruttura di intelligenza artificiale? Diamo il benvenuto a enormi spese di capitale e operative continue, risorse inutilizzate e complessità operative di cui nessuno ha bisogno.
Ancor più che in altre iniziative IT, gli esperti di scalabilità hanno concordato sul fatto che limitarsi a concentrare la potenza di elaborazione sui problemi non sia una strategia vincente. Eppure, rimane una tentazione, anche se non del tutto intenzionale.
"I lavori con esigenze minime di intelligenza artificiale vengono spesso indirizzati verso costose infrastrutture GPU o TPU", ha affermato Mine Bayrak Ozmen, un veterano della trasformazione che ha guidato implementazioni di intelligenza artificiale aziendale presso aziende Fortune 500 e un centro di eccellenza in intelligenza artificiale per una delle principali società di consulenza globali.
Ironicamente, ha affermato Ozmen, anche co-fondatrice di Riernio, azienda di piattaforme di intelligenza artificiale, "è semplicemente perché le scelte di progettazione incentrate sull'intelligenza artificiale hanno superato i principi organizzativi più classici". Purtroppo, le inefficienze di costo a lungo termine di tali implementazioni possono essere mascherate da forti sconti da parte dei fornitori di hardware, ha aggiunto.
Cosa dovrebbe dunque guidare le scelte strategiche e tattiche? Un aspetto che non dovrebbe essere preso in considerazione, concordano gli esperti, è un ragionamento paradossalmente errato: poiché l'infrastruttura per l'intelligenza artificiale deve offrire prestazioni elevatissime, processori più potenti e hardware più performanti devono essere migliori.
"Il ridimensionamento dell'IA non riguarda il calcolo della forza bruta", ha affermato Thompson di Hackett, che ha guidato numerosi grandi progetti globali di IA ed è autore di The Path to AGI: Artificial General Intelligence: Past, Present, and Future , Pubblicato a febbraio. Lui e altri sottolineano che l'obiettivo è avere l'hardware giusto al posto giusto al momento giusto, non il più grande e il più cattivo in circolazione.
Secondo Ozmen, gli scalatori di successo adottano "un approccio basato sulla giusta dimensione per una corretta esecuzione". Ciò significa "ottimizzare il posizionamento del carico di lavoro (inferenza vs. training), gestire la localizzazione del contesto e sfruttare l'orchestrazione basata su policy per ridurre la ridondanza, migliorare l'osservabilità e favorire una crescita sostenibile".
A volte l'analisi e la decisione sono semplici come un tovagliolo. "Un sistema di intelligenza artificiale generativa al servizio di 200 dipendenti potrebbe funzionare benissimo su un singolo server", ha affermato Thomspon. Ma per iniziative più complesse, la situazione è completamente diversa.
Prendiamo un sistema aziendale core basato sull'intelligenza artificiale per centinaia di migliaia di utenti in tutto il mondo, che richiede failover cloud-native e notevoli capacità di scalabilità. In questi casi, ha affermato Thompson, il corretto dimensionamento dell'infrastruttura richiede esercizi di definizione dell'ambito, distribuzione e scalabilità disciplinati e rigorosi. Qualsiasi altra soluzione è un'azione scorretta e sconsiderata.
Sorprendentemente, una disciplina così basilare della pianificazione IT può essere trascurata. Spesso sono le aziende, desiderose di ottenere un vantaggio competitivo, a cercare di accelerare i tempi destinando budget infrastrutturali sproporzionati a un progetto chiave di intelligenza artificiale.
La nuova ricerca di Hackett mette in discussione alcuni presupposti di base su ciò che è realmente necessario in termini di infrastrutture per scalare l'intelligenza artificiale, fornendo ulteriori motivi per condurre un'analisi preliminare rigorosa.
L'esperienza pratica di Thompson è istruttiva. Costruendo un sistema di assistenza clienti basato sull'intelligenza artificiale con oltre 300.000 utenti, il suo team si è presto reso conto che era "più importante avere una copertura globale che un'enorme capacità in una singola sede". Di conseguenza, l'infrastruttura è distribuita tra Stati Uniti, Europa e la regione Asia-Pacifico; gli utenti vengono indirizzati dinamicamente in tutto il mondo.
Il consiglio pratico da trarre? "Mettete delle recinzioni intorno alle cose. Sono 300.000 utenti o 200? La portata detta l'infrastruttura", ha detto.
Una moderna strategia infrastrutturale di intelligenza artificiale multilivello si basa su processori e acceleratori versatili, ottimizzabili per diversi ruoli lungo tutto il continuum. Per informazioni utili sulla scelta dei processori, consultate "Oltre le GPU" .
Fonte: VentureBeat
Ora hai un'idea nuova di cosa può e dovrebbe essere un'infrastruttura scalabile per l'IA, una buona idea del punto ottimale e della portata dell'investimento, e di cosa serve e dove. Ora è il momento degli acquisti.
Come sottolineato nell'ultimo numero speciale di VentureBeat, per la maggior parte delle aziende la strategia più efficace sarà quella di continuare a utilizzare infrastrutture e apparecchiature basate sul cloud per ampliare la produzione di intelligenza artificiale.
I sondaggi condotti su grandi organizzazioni mostrano che la maggior parte è passata da data center on-premise personalizzati a piattaforme di cloud pubblico e soluzioni di intelligenza artificiale preconfigurate. Per molte, questo rappresenta un passo avanti nella continua modernizzazione, che evita ingenti esborsi di capitale iniziali e la ricerca di personale qualificato, offrendo al contempo una flessibilità critica per far fronte a requisiti in rapida evoluzione.
Nei prossimi tre anni, Gartner prevede che il 50% delle risorse di cloud computing sarà dedicato ai carichi di lavoro di intelligenza artificiale, rispetto a meno del 10% attuale. Alcune aziende stanno inoltre aggiornando i data center on-premise con elaborazione accelerata, memoria più veloce e reti a banda larga.
La buona notizia: Amazon, AWS, Microsoft, Google e un universo in rapida espansione di provider specializzati continuano a investire somme impressionanti in offerte end-to-end create e ottimizzate per l'intelligenza artificiale, tra cui infrastrutture full-stack, piattaforme, elaborazione (compresi i provider cloud GPU) , HPC, storage (hyperscaler più Dell, HPE, Hitachi Vantara), framework e una miriade di altri servizi gestiti.
"In particolare per le organizzazioni che vogliono muovere rapidamente i primi passi", ha affermato Wyatt Mayham, consulente capo per l'intelligenza artificiale presso Northwest AI Consulting, i servizi cloud rappresentano un'ottima scelta, semplice e immediata.
Ad esempio, in un'azienda che già utilizza Microsoft, "Azure OpenAI è un'estensione naturale [che] richiede poca architettura per funzionare in modo sicuro e conforme", ha affermato. "Evita la complessità di creare un'infrastruttura LLM personalizzata, offrendo comunque alle aziende la sicurezza e il controllo di cui hanno bisogno. È un ottimo caso d'uso rapido e vincente".
Tuttavia, l'ampia gamma di opzioni a disposizione dei decisori tecnologici ha un altro lato negativo. Selezionare i servizi appropriati può essere scoraggiante, soprattutto perché sempre più aziende optano per approcci multi-cloud che abbracciano più provider. Problemi di compatibilità, sicurezza coerente, responsabilità, livelli di servizio e requisiti di risorse on-site possono rapidamente intrecciarsi in una rete complessa, rallentando lo sviluppo e l'implementazione.
Per semplificare le cose, le organizzazioni potrebbero decidere di affidarsi a uno o due fornitori primari. In questo caso, come nell'hosting cloud pre-IA, incombe il rischio di un lock-in da parte del fornitore (sebbene gli standard aperti offrano la possibilità di scelta). Su tutto questo incombe lo spettro dei tentativi passati e recenti di migrare l'infrastruttura verso servizi cloud a pagamento, solo per scoprire, con orrore, che i costi superano di gran lunga le aspettative iniziali.
Tutto ciò spiega perché gli esperti affermano che la disciplina IT 101, che consiste nel sapere il più chiaramente possibile quali prestazioni e capacità sono necessarie (ai margini, in sede, nelle applicazioni cloud, ovunque), è fondamentale prima di iniziare l'approvvigionamento.
L'opinione diffusa suggerisce che la gestione interna delle infrastrutture sia riservata principalmente alle imprese con budget elevati e ai settori fortemente regolamentati. Tuttavia, in questo nuovo capitolo dell'IA, gli elementi chiave interni vengono rivalutati, spesso nell'ambito di una strategia ibrida di dimensionamento.
Prendiamo Microblink, che fornisce servizi di scansione di documenti e verifica dell'identità basati sull'intelligenza artificiale a clienti in tutto il mondo. Utilizzando Google Cloud Platform (GCP) per supportare carichi di lavoro di machine learning ad alto rendimento e applicazioni ad alta intensità di dati, l'azienda ha rapidamente riscontrato problemi di costi e scalabilità, ha affermato Filip Suste, responsabile tecnico dei team della piattaforma. "La disponibilità della GPU era limitata, imprevedibile e costosa", ha osservato.
Per affrontare questi problemi, i team di Suste hanno adottato una strategia di cambiamento, spostando i carichi di lavoro informatici e l'infrastruttura di supporto on-premise. Un elemento chiave del passaggio all'ibrido è stato un sistema di storage a oggetti cloud-native ad alte prestazioni di MinIo.
Per Microblink, riportare in casa l'infrastruttura chiave ha dato i suoi frutti. Ciò ha ridotto i costi correlati del 62%, ridotto la capacità inutilizzata e migliorato l'efficienza della formazione, ha affermato l'azienda. Fondamentalmente, ha anche ripreso il controllo sull'infrastruttura di intelligenza artificiale, migliorando così la sicurezza dei clienti.
Makino, produttore giapponese di centri di lavoro computerizzati, presente in 40 paesi, si è trovato ad affrontare un classico problema di carenza di competenze. Gli ingegneri meno esperti impiegavano fino a 30 ore per completare riparazioni che i lavoratori più esperti potevano completare in otto.
Per colmare il divario e migliorare il servizio clienti, la dirigenza ha deciso di trasformare vent'anni di dati di manutenzione in competenze immediatamente accessibili. La soluzione più rapida ed economica, hanno concluso, è integrare un sistema di gestione dei servizi esistente con una piattaforma di intelligenza artificiale specializzata per i professionisti dei servizi di Aquant.
L'azienda afferma che l'adozione della tecnologia più semplice ha prodotto ottimi risultati. Invece di valutare laboriosamente diversi scenari infrastrutturali, le risorse si sono concentrate sulla standardizzazione del lessico e sullo sviluppo di processi e procedure, ha spiegato Ken Creech, direttore dell'assistenza clienti di Makino.
La risoluzione remota dei problemi è aumentata del 15%, i tempi di risoluzione sono diminuiti e i clienti ora hanno accesso self-service al sistema, ha affermato Creech. "Ora, i nostri ingegneri pongono una domanda in linguaggio semplice e l'intelligenza artificiale trova rapidamente la risposta. È un vero e proprio fattore wow."
Presso Albertsons, una delle più grandi catene alimentari e farmaceutiche del Paese, i team IT impiegano diverse tattiche semplici ma efficaci per ottimizzare l'infrastruttura di intelligenza artificiale senza aggiungere nuovo hardware, ha affermato Chandrakanth Puligundla, responsabile tecnico per l'analisi dei dati, l'ingegneria e la governance.
Il Gravity Mapping, ad esempio, mostra dove sono archiviati i dati e come vengono trasferiti, che si tratti di dispositivi edge, sistemi interni o sistemi multi-cloud. Questa conoscenza non solo riduce i costi di uscita e la latenza, ha spiegato Puligundla, ma guida anche decisioni più consapevoli su dove allocare le risorse di elaborazione.
Allo stesso modo, ha affermato, l'utilizzo di strumenti di intelligenza artificiale specializzati per l'elaborazione del linguaggio o l'identificazione delle immagini occupa meno spazio, spesso garantendo prestazioni migliori e risparmi rispetto all'aggiunta o all'aggiornamento di server più costosi e computer generici.
Un altro trucco per evitare i costi: monitorare i watt per inferenza o ora di formazione. Guardare oltre la velocità e i costi, concentrandosi su parametri di efficienza energetica, dà priorità alle prestazioni sostenibili, cruciali per modelli e hardware di intelligenza artificiale sempre più assetati di energia.
Puligundla ha concluso: "Possiamo davvero aumentare l'efficienza attraverso questo tipo di preparazione consapevole".
Il successo dei progetti pilota di intelligenza artificiale ha portato milioni di aziende alla fase successiva del loro percorso: l'implementazione di applicazioni generative e LLM, agenti e altre applicazioni intelligenti con elevato valore aziendale in una produzione più ampia.
L'ultimo capitolo dedicato all'intelligenza artificiale promette grandi ricompense per le aziende che assemblano strategicamente infrastrutture e hardware in grado di bilanciare prestazioni, costi, flessibilità e scalabilità tra edge computing, sistemi on-premise e ambienti cloud.
Nei prossimi mesi, le opzioni di scalabilità si amplieranno ulteriormente, poiché gli investimenti del settore continueranno a riversarsi in data center di grande portata, chip e hardware edge (AMD, Qualcomm, Huawei), infrastrutture full-stack AI basate su cloud come Canonical e Guru, memoria context-aware, dispositivi plug-and-play sicuri on-prem come Lemony e molto altro ancora.
La saggezza con cui i leader IT e aziendali pianificano e scelgono l'infrastruttura per l'espansione determinerà gli eroi delle storie aziendali e gli sfortunati condannati al purgatorio dei piloti o alla dannazione dell'intelligenza artificiale.
venturebeat




